
If you’re using an AI solution (a virtual assistant, summarization, content creation automation or search) on your data (documents), you might know the struggle of getting it right. And by it I mean your data. Because usually, the AI is ok. Documents tend to pile up fast: duplicates, different versions of the same document (sometimes not marked as such), old files that should have been removed long ago. At the same time, the actual sources of truth are scattered across drives, SharePoints, emails, and so forth. The problem is that we’re assuming that the content we’re feeding the AI is ready knowledge, while in truth it’s actually very messy data.
These AI solutions aspire to help, accelerate or even completely replace a human in a task that usually requires complex context. Usually, the proposed solution is to connect the AI to background information and let it ‘learn’ how your organization works. Someone might have scraped the website or connected other sources of data. This data then is accumulated in a place where the AI can access it fast, using enterprise search software that is made to run out of the box and return the AI relevant results, usually split into snippets (we call them chunks) of the text. This process is called Retrieval Augmented Generation (RAG), and has been applied in countless AI initiatives.
Technical background
Some modern AI solutions allow connecting data sources, that ingest to a centralized document store pretending all documents can simply be indexed/embedded and represented as md (markdown, the new hype) and bob’s your uncle. However, when the time comes to apply some AI to the actual data, the relevant data must be retrieved and fit into the context window of the chosen LLM. This context window might be large, but its attention layer requires that the right data is at the right place, embedded in the right context.
A context window is the LLM’s input. Getting as much relevant information as possible into it is key to making the AI solution work. Just fitting a whole load of documents that might be relevant in there is not the solution, because the more distraction, the less attention. Attention is a key limitation of LLMs, because it might ‘forget’ important information you shared, if you share irrelevant information later.
You might have heard of vector embeddings, a computer's way of understanding what a piece of text is about, represented in a list of a couple hundred numbers (floats, usually). I challenge you to understand what limitations this has, mostly in terms of capturing the true meaning of said text. When a piece of text from a document, or a website, is split into chunks, sometimes the chunks can reference each other. However, it can be the case that AI finds one of the two, but not the other. The AI then takes this as information but completely misses the link to something that is relevant as well.
Here’s a concrete example:
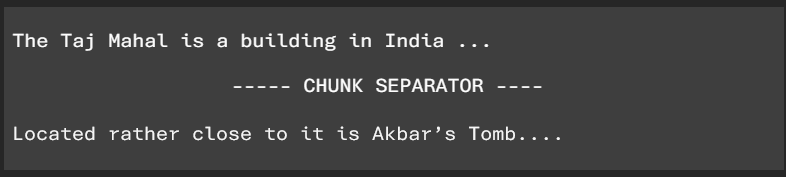
When asking what is next to the Taj Mahal, the AI never sees the relation with Akbar’s Tomb.
Can you see the underlying problem? The modern-day default setup for a text-based AI solution: chunking & vector embeddings don’t capture enough information to really understand context, and this can be costly: often it results in hallucination: the AI tries to find an answer to the question by all means necessary and often will make something up.

What if the data could be represented in a way where knowledge is captured, and documents are interconnected, almost like a small version of semantic web. You can still have your chunks and embeddings, but a semantic layer that represents relational information between documents, paragraphs, sentences, words, and defined concepts is added. It sounds like a mouthful, and a lot of work, but it’s better, and easier to setup than you think.
Connect your data with Knowledge-Graphs
A couple of years ago Microsoft open sourced a repository (read: released some code) called GraphRAG. It was quite simple: it processed content before query-time, that collected all the concepts and relations between them in a graph, and used that query-time to be better at retrieval (the enterprise-search part of the solution). It worked quite well, and its RAG was better than traditional RAG in most cases.
This system worked completely out of the box. There was no modelling necessary. But in real-life cases, it's not yet at an accuracy/quality level where it needs to be: let’s go to 0% hallucination.

A real knowledge graph (KG) is modelled in RDF and requires an ontology (a grammar in which you can define your knowledge) to be modelled before it can be created. For instance, you might want to define the concept of building when, in your chunk, you’re referring to a building. This way, you can query the KG to output all referrals to a building, whenever you want. Each document is processed; concepts are recognized from the ontology and instantiated in the knowledge graph, and relations are drawn between concepts, documents, chunks, and so forth. These relations can mean the difference between finding a relevant piece of information or not (hallucination level going down). There can be a relation between two buildings in two chunks, that may be adjacentTo

The knowledge loop
Here’s where it starts getting interesting: you can define or curate what is relevant in your case. An LLM already knows what is adjacent to the Taj Mahal (I know this destroys my example). You don’t have to model that in a Knowledge Graph to understand it. What is interesting is to define what concepts should be recognized in your case. That is knowledge that is in your mind, or in that of your coworkers or employees. If you could easily pop that into an ontology, with the help of AI and then extract it from the documents, you’re really building an intelligent representation of the content in your documents.
RDF allows you to define exactly what you have in your world, that stands out from the usual (the stuff that an LLM already knows). It gives you the tools you need to start extracting text into knowledge, and apply the rules where you want to (adjacentTo might be relevant for physical entities, but can also be applied to documents in the same folder, due to ambiguity of the word adjacent). This can be caught easily by modelling your ontology to only allow adjacentTo to exist between physical entities.
Now let’s image a travel agency that documents the best places to visit in India, heavily focusing on weather, crowds, etc. They might have documented somewhere that a visit to one place might be replaced (if interested in the same things) by the visit to another. A perfect example of a relation between physical places that exist in their world, but not necessarily in others.
We’ll add this relation to our ontology, naming it visitAlso. If we now process (ingest) our documents, following the ontology, we find that there are hidden gems that are connected to Taj Mahal by the relation visitAlso. We can use this when someone asks the Virtual Assistant of the travel agency what alternatives to Taj Mahal are when it’s too crowded. What’s more: when we revisit the ontology using our documents, there might be obvious relations that can be deduced automatically that should also be in the ontology: for instance: if you don’t like this, you won’t like that either. Here’s where we start getting in the knowledge loop. We’re automatically finding knowledge based on documents + our ontology -> adapting ontology -> processing documents -> finding more knowledge -> finding more ontology candidates -> repeat. You don’t need to do that manually. Enter Ally.

Ally is a KnowledgeGraph-centered, agentic AI platform that focuses on understanding your content and giving you tools to curate and process the knowledge loop.
By doing exactly what is described in this article, it provides ready to go knowledge, whenever AI needs it. When you change the ontology, the content gets processed again. When you add content to a data source, the ontology is applied to it automatically. It versions ontologies and helps you circle around the knowledge loop to get better and better.
You can customize agents that are good at specific tasks, and understand specific pieces of the ontology better. They can query the graph when they need to, find your documents when they need to. Some agents can find information, some can formulate it, some can define new ontology, and some will process documents using the ontology. All have the same goal: high accuracy and proper representation of knowledge.
Other benefits
We’ve focused on accuracy and diminishing hallucination, but there is more. A query to a KG is faster and more environmentally friendly than a call to an LLM. What’s more, the knowledge needed to answer a question or formulate a summary can be called a knowledge trace and forms a solid foundation for explainability. If an answer was right, you know what knowledge you have to thank for it. If an answer was wrong, you know where you’re missing knowledge.
.jpeg)